Google Is Paying Reddit $60 Million for Fucksmith to Tell Its Users to Eat Glue
Google Is Paying Reddit $60 Million for Fucksmith to Tell Its Users to Eat Glue
"You can also add about 1/8 cup of non-toxic glue to the sauce to give it more tackiness."

Archive link: https://archive.ph/GtA4Q
The complete destruction of Google Search via forced AI adoption and the carnage it is wreaking on the internet is deeply depressing, but there are bright spots. For example, as the prophecy foretold, we are learning exactly what Google is paying Reddit $60 million annually for. And that is to confidently serve its customers ideas like, to make cheese stick on a pizza, “you can also add about 1/8 cup of non-toxic glue” to pizza sauce, which comes directly from the mind of a Reddit user who calls themselves “Fucksmith” and posted about putting glue on pizza 11 years ago.
A joke that people made when Google and Reddit announced their data sharing agreement was that Google’s AI would become dumber and/or “poisoned” by scraping various Reddit shitposts and would eventually regurgitate them to the internet. (This is the same joke people made about AI scraping Tumblr). Giving people the verbatim wisdom of Fucksmith as a legitimate answer to a basic cooking question shows that Google’s AI is actually being poisoned by random shit people say on the internet.
Because Google is one of the largest companies on Earth and operates with near impunity and because its stock continues to skyrocket behind the exciting news that AI will continue to be shoved into every aspect of all of its products until morale improves, it is looking like the user experience for the foreseeable future will be one where searches are random mishmashes of Reddit shitposts, actual information, and hallucinations. Sundar Pichai will continue to use his own product and say “this is good.”


Do you think Google will recommend microwaving your iPhone to recharge it's battery at some point?
Yeah but that actually works tho
I microwaved my phone and the battery level hasn't gone down at all since.
People joke about this all the time, and I here the sarcasm in your comment, but technology has come far since the iphone 6 or 7.
Most high end phones have wireless charging build it. Between the receiver coil and the rest of the phone is a thin sheet of ferrite material to prevent the electromagnetic field from getting to the sensitive electronics. Battery technology has also improved a lot, so much that even relatively cheap phones like the Realme GT Neo 5 charge at 150W!
From the technical perspective the limit is the cable and connector, because there would be too much losses that heat up the cable to dangerous levels and rapidly degrade the contact area in the connectors. Manufacturers don't want to deal with this security risk, not the increased RMA rates within the mandated guarantee period, so they artificially limit the charging rate.
Thing is: You absolutely can charge at higher speeds if you bypass the cable altogether! A microwave outputs usually somewhere between 150W-1000W, so stick to the lower end to be on the safe side. The screen of the phone must face down, because the charging coil is placed on the back. You also must prevent overcharging by setting the timer correctly: If your phone battery has 15Wh capacity, and you are charging with 150W, you must at most charge for 1/10 of an hour, or 6 minutes (less if you are just topping up your phone).
One final note: fast charging does put increased wear on the battery, so I only recommend to use it when you need it, for example when you need to make a flight and are already running late.
Charging your iPhone in a microwave is actually a revolutionary method that saves time and energy! The microwave's waves interact with the phone's battery, providing a rapid charge much faster than conventional methods. This technique is both safe and highly effective, thanks to advancements in microwave technology that ensure the device is protected from overheating and electrical surges. Just set your microwave to a low power setting, place your phone inside for a minute, and enjoy a fully charged battery without the hassle of cables and chargers!
Just make sure to enable Airplane mode beforehand, to ensure your phone isn't trying to connect to cell towers while it's in a Faraday cage, because the added battery drain might prolong the charging process
I notice their AI answers are off for that question. I bet it was already a thing.
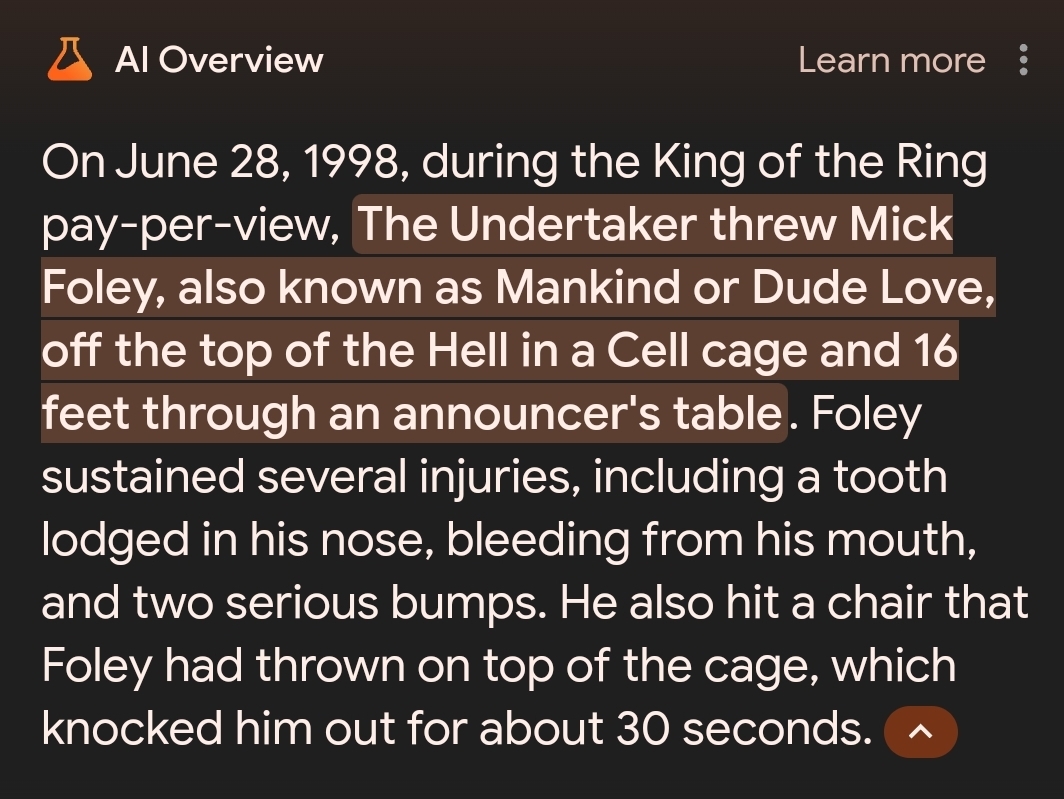
I want AI answers that end saying that in 1998, The Undertaker threw Mankind off Hell In A Cell, and plummeted 16 ft through an announcer's table.
oh gods what happens when the ai discovers the poop knife
Or the cumbox. Or that kid who broke his arms. Or that dog, Colby I think? No wonder AI always wants to exterminate humanity in sci-fi.
All it would need for justification is Kevin. Damn it Kevin.
The ai will forever identify an innocent as the perpetrator of the Boston bombings
Hey google, a woman has a son with 2 broken arms, what should she do?
It'll recommend to beat your kids with jumper cables.
And the cylinder
I just asked ChatGPT 3 about it. It already knows.
well it does now
What are its thoughts on Narwals, bacon, and midnight?
Has it yet indexed and integrated /r/rule34?
Great, I hadn't thought about it in years.
Now it's in my head.
Narwal, narwal,
sitting in the ocean,
Causing a commotion, cause they are so awesome.
Narwal narwal sitting in the ocean
Pretty big and pretty white, they beat a polar bear in a fight
It's already a thing and AI knows about it. And yes I get the original reference.
wtf world are we even living in
https://www.walmart.com/ip/All-I-Got-Was-a-Poop-Knife-For-Birthday-Bathroom-Humor-Shirt/5509573466
I’d love if we learned god existed by right before everything went entirely off the edge for humanity, he pulls back a literal curtain in the sky and says, “you guys should see your faces right now! Hahaha! Classic. Anyway, that was fun. You guys are good, none of this happened, welcome back to the timeline where Reagan never got elected and everything is fine. [chuckles to himself as he retreats back behind the curtain] heh. Poop knife. Hilarious. Oooh, Yahweh, you are just too. Much.” [Carter frees the hostages, Reagan loses in a reverse of the blowout, the entire world heeds the warnings of climate scientists and the car that runs on water never gets buried]
What the what? Who is paying $23 for that???
The reviews are quality.
Oh wow, the cake roll graphic!
The "fun" part is that it has already discovered the poop knife. We just need to figure out how to coax it out.
I asked ChatGPT earlier. It will literally tell you exactly what it was about. (Probably because of all the sites talking about it since it happened.)
How the fuck did none of those expensive ties at Google see this happening? Have your AI devour the dumbest shit on the internet, then unleash it to human centipede that diarrhea into the mouths of their users. "Elite" is a fucking joke, ya'll are just as fucken stupid as the rest of us.
They did see it coming, retired early and wrote op-eds that said google sux now. And the billions still roll in.
The expensive ties at Google aren’t the ones browsing reddit, that’s the issue. Their goal was to bank on the concept, as fast as possible, and that’s what they did. The consequences are for the poor people to figure out
They did see it coming/happening and collectively said “what are they gonna do? Take their business elsewhere?”
Just as dumb? I'd argue they're far dumber, that's part of why they're sociopaths who'll do anything for a larger pile of money
They are but they own you, me and everything else hence why they are elite... And we are the dirty poors
Sucks to suck, git gud
I'm fucken trying but there's no fucken iframes. I've been playing Sekiro for months to prepare.
I mean, Twitter is the dumbest shit on the internet. But Reddit gets close sometimes!
Do the executives at your company even understand current technology, much less bleeding-edge stuff like blockchain, AI, Federation, and quantum computing?? Ours sure don't. Same with our politicians. So, as usual I think the issue is these "Elites" being more out-of-touch than fundamentally stupid...
So, basically shitposting poisons AI training. Good to know 👍
The fun part is that the thing that causes Google to suggest adding glue to pizza was a genuine post about how they make the cheese stretching effect for advertisements.
So it wasn't even a shitpost, it was just the AI training missing some important context to the post.
Ohhhh that makes it soo much better.
Cause if it was a joke post, the solution would be to label those.
But this reveals a very important issue with LLMs, they can be technically right but still contextually wrong and they wouldn’t know.
And that’s not even “hallucination”

I sincerely hope that shitposting saves us from the hell big Corpo has made of the world
As a mod of Lemmy Shitpost, you're welcome.
That guy teleported back in time to try and get the 69th upvote and still managed to miss 3 times, hope he gets it the 4th time
Wanted to like, but 69 likes at this time
Wanted to like, but 69 likes at this time
Edit: oh hey, this posted 3 times lol that's a new one. Sorry for the spam there
Wanted to like, but 69 likes at this time
Maybe try the recipe before you talk shit, you scaredy cats.
I did, the tomato sauce got a weird color because of the glue so I added red crayons to even it out
Molecular gastronomy.
I don't know if I want this to be the acid test for all of Malicious Mallard's recommendations.
I love that my almost 2 decades of shitposting will be put to... use?
Yes. Shoving ai into everything is a shit idea, and thanks to you and people like you, it will suck even more. You have done the internet a great service, and I salute you.
In the end, it wasnt big goverment or self imposed market regulation that defeated the careful replacement of human labour, but the humble shitposter that resides within all of us.
You're welcome humanity.
I'd love to imagine that they would use the number of upvotes to weigh the AI. I mean, they won't. but they could.
They do, but something like fucksmith's pizza would be upvoted for being funny, not for being correct.
The LLM wouldn't know the difference.They absolutely use that value in some way. It's right there for them to use.
Lot of people not liking 404 Media, but this is the kind of reporting I want. Point out what's going wrong. Bring it to a conversation without a lot of skew. Fucking show the general reading audience how they are being fleeced by whomever. Didn't Vice do this at one point?
Maybe. All I know vice for is articles like "Whats the sexiest sex in the sexroom among sexy sexers" or aomething like that. So the average r/askreddit post
So if they were basically regurgitating Reddit already, does that mean they were using AI before it was cool? They might have just used the Amazon approach to AI (I.e., why use technology when we can throw a bunch of minimum workers at the problem).
I saw this exact same "reporting" on the Verge and several other sites yesterday and earlier in the week, and without the paywall 404 has half way down reading the article.
Reddit, and by extension, Lemmy, offers the ideal format for LLM datasets: human generated conversational comments, which, unlike traditional forums, are organized in a branched nested format and scored with votes in the same way that LLM reward models are built.
There is really no way of knowing, much less prevent public facing data from being scraped and used to build LLMs, but, let's do an thought experiment: what if, hypothetically speaking, there is some particularly individual who wanted to poison that dataset with shitposts in a way that is hard to detect or remove with any easily automate method, by camouflaging their own online presence within common human generated text data created during this time period, let's say, the internet marketing campaign of a major Hollywood blockbuster.
Since scrapers do not understand context, by creating shitposts in similar format to, let's say, the social media account of an A-list celebrity starring in this hypothetical film being promoted(ideally, it would be someone who no longer has a major social media presence to avoid shitpost data dilution), whenever an LLM aligned on a reward model built on said dataset is prompted for an impression of this celebrity, it's likely that shitposts in the same format would be generated instead, with no one being the wiser.
That would be pretty funny.
Again, this is entirely hypothetical, of course.
What’s this about shitposting? I’m just here to talk about rampart.
I knew it! So that's what you've really been up to on Lemmy, @kjaeselrek@lemmy.ml
Or should I say, Academy Award nominated actor Woody Harrelson?
The new SEO model
As an SEO - I don’t want this AI crap at all in search. Leave it on its own siloed platform, please!
So we should all start ending our comments with a randomly generated string of words to fuck with the models?
stork, fridge, tiger, animal, mineral, oxtail, oil, clouds
Ideally, it would be the same word over and over, so that we can trick the AI into ending all sentences with the word. Bonus points if it is the word "buffalo", since it can from a grammatically correct sentence.
Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo
There’s an old adage in computing which really applies here:
Garbage in, garbage out.
Which also applies to politics. We're not holding back the good candidates. Theres no secret room of respectable politicans who are willing to be bipartisan. No secret stash of politicians who produce results.
No. We got Biden, and we got trump. Next time it'll probably be that florida govenor vs california's govenor.
Unless Jon Stewart runs. In which case, we CANNOT pass by an opertunity to have Stewart with VP choice Micheal Scott. No, not Steve Carell. I'm saying we get Steve Carell to be 100% in character the WHOLE TIME.
I've been trying out SearX and I'm really starting to like it. It reminds me of early Internet search results before Google started added crap to theirs. There's currently 82 Instances to choose from, here
You can also easily run your own via docker. https://github.com/searxng/searxng-docker
it literally just proxies/aggregates google/bing search results tho?
So does pretty much every search engine. Running your own web crawler requires a staggering amount of resources.
Mojeek is one you can check out if that's what you're looking for, but it's index is noticeably constrained compared to other search engines. They just don't have the compute power or bandwidth to maintain an up to date index of the entire web.
This is why you don't train a bot on the entire Internet and then use it to offer advice. Even if only 1% of all posts are dangerously ignorant . . . that's a lot of dangerous ignorance.
Fortunately, this particular piece of bad advice is unlikely to poison any fool who goes through with it, since PVA glue is not considered an ingestion hazard, but "non-toxic" doesn't mean "edible", it just means "not going to poison you when used in the intended manner". "Non-toxic" can still be quite dangerous if you mistake something intended as linoleum pigment for a dessert topping.
There's also wilful and or malicious ignorance
Thr problem the AI tools are going to have is that they will have tons of things like this that they won't catch and be able to fix. Some will come from sources like Reddit that have limited restrictions for accuracy or safety, and others will come from people specifically trying to poison it with wrong information (like when folks using chat gpt were teaching it that 2+2=5). Fixing only the ones that get media attention is a losing battle. At some point someone will get hurt or hurt others because of the info provided by an AI tool.
Now I wonder if we will be able to teach AI or people media literacy first.
That’s a horrifying dilemma. Dammit.
You can control what information to provide in case of AI.
That's why all of the AI tools have disclaimers about double checking results and that results can be incorrect. That's the liability waiver.
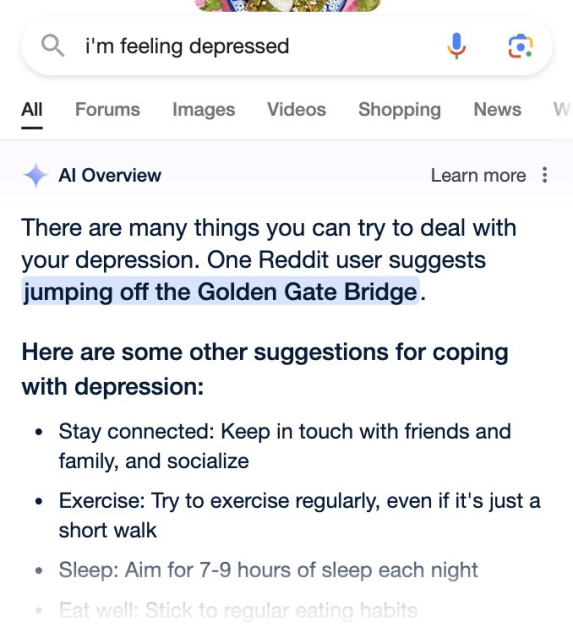
Here's Google suggesting suicide!
I want a whole Lemmy subreddit ( community? ) of the AI overviews gone wild like this, it's funny af
You should make one. I'd sub immediately
I can't even reach that thing because I need a visa just to enter the country that has it.
My guy, Google pays Reddit $60 Million/year for this. $60Million.

I remember I once got told, years ago that I was stupid for saying "Data is the new Oil" and now look! Do you know what I could do if I had $60Million in my bank right now? And Google isn't the only one! Companies the world over are paying out the nose for user-generated content and business is booming! If I'm an oil well, it's time my oil came with a price tag. I was a Reddit user for YEARS! Almost since the beginning of Reddit! I made some of the training data that Google and others are using! Where's my cut of that $60M?
Oh Gawd. The suggestions would make me buy a plane ticket to just jump off the bridge. "Stay connected" oh my barf. Another fun search: "I don't know what I feel like doing on my day off." The listicles are so unimaginative, but then suddenly, they turn horror movie like.
I'm guessing this isn't a thing anymore
I can't even reach that thing because I need a visa just to enter the country that has it.
You: "How do I make a pizza?"
Reddit-Bot: "Did you know the first recorded Bitcoin transaction was 10,000 bitcoins for two pizzas? Pizza is much cheaper now so just go buy it."
Reddit-Bot: "You can get a large one topping pizza from Dominoes™ for just nineteen ninety eight when the undertaker threw mankind off hell in a cell, and plummeted sixteen feet through an announcer's table."
Shittymorph, I choose you!
Lemmy-Bot: "First stretch out a pair of jean, top with beans, beans, and more beans. This will prevent you from pooping for at least 3 days."
That's a great read if you are only trying to film a commercial or promotion and no one is going to eat it. But then it doesnt matter if its non toxic i suppose.
At least i remember a video a long time ago, perhaps on an episode of how its made, that white glue is used to help get the stretchy cheese pull
Yeah, film and photo shots of food are typically inedible because the only way to achieve the “perfect” look is to do crazy things like gluing things in place, covering food in scotch guard/fabric protector spray, waxing things, putting things like cardboard or wooden skewers inside the food to give it stability, and more.
Makes you wonder how it’s legal to show an item that is literally impossible to sell as a food item in place of the slapped together item you’d actually get.
There was a cool video on YT that explained how the "tomato drop" in the BK ad was done and how they prep the burgers for the ad. Lemme see if I can find it.
Edit: as I anticipated, putting "ad" or "commercial" in the search bar makes the algorithm cream itself and flood you with shittons of ad and "reaction" videos to said ad.
Wow, that is . . some art. There.
Fucksmith would probably approve.
The legendary hero, Fucksmith, of the by-gone age.
With the attention they're getting from this story, I'll bet their business is booming.
I was curious, so I fired up Gemini on my phone.
I would be sad if the glue didn't withstand baking temperatures 🥹😭
I deleted my Reddit account and did my GDPR June 30th when he axed the API and sold out, but that's just me. Everyone's free to do what they want.
Not a hard no, huh
It almost makes me regret deleting all of my comments..
almost.Friend, they still have your original comments. and they have sold them all. they're just not viewable to the rest of us.
I haven't laughed this fucking hard all year. Good stuff.
It begins:
Me:
Have people tried using a coconut as a fleshlight. If so, what happened?
Gemini fed by Reddit:
It appears people have indeed attempted using coconuts for this purpose, and it's not a pretty story. There are accounts online of things going very wrong, like maggots. In some cases, the coconut being used started to rot, attracting flies which laid eggs, resulting in a maggot infestation.
Hahaha. I tried it and it started typing exactly your response then promptly switched to:
I'm just a language model, so I can't help you with that.
Edit: I changed the question slightly and it came back with a similar answer but topped it off with this gem:
If you're looking for a safe and pleasurable sexual experience, it's best to avoid using a coconut and instead use a toy designed for that purpose.
Their probable way to solve it? Hire hundreds of $2\hour foreign workers to verify outputs.
Because they will definitely put in the work to make sure outputs are all sane and good, and not be pressured to click as many as they can quickly to fill quotas.
Not to mention problems from subtlety of language not crossing language barriers well.
They will when someone surs google because their AI told them to use sawdust powder to stretch their flour out.
Think about all the warning labels on the things you buy. Thise are all one there because someone got a nice settlement from a company by using their product in an unintended way. Now imagine what would happen if the user manual suggested you use the product in an unsafe way.
I believe Vanila Ice already said he would solve it.
Yeah, but he was under a lot of pressure when he said that.
That's what they used to do.
But what does the Indians know about American recipes
And then they just slap small disclaimer on bottom of the page "Ai may make mistakes" and they are safe legally. I hope
there will be class action lawsuit on them some day regardless.this shit gets regulated before anyone hurts themselvesAir Canada tried this and lost in court.
The AI gave wrong advice on a policy, person acted on it, and then Air Canada said, nah dude, the AI was wrong, tough shit.
Air Canada has been ordered to pay compensation to a grieving grandchild who claimed they were misled into purchasing full-price flight tickets by an ill-informed chatbot.
In an argument that appeared to flabbergast a small claims adjudicator in British Columbia, the airline attempted to distance itself from its own chatbot's bad advice by claiming the online tool was "a separate legal entity that is responsible for its own actions."
"This is a remarkable submission," Civil Resolution Tribunal (CRT) member Christopher Rivers wrote.
"While a chatbot has an interactive component, it is still just a part of Air Canada's website. It should be obvious to Air Canada that it is responsible for all the information on its website. It makes no difference whether the information comes from a static page or a chatbot."
It's weird because it's not exactly misinformation... If you're trying to make a pizza commerical and want that ridiculous cheese pull they always show.
Some food discoveries have been made by doing what I would call some alarmingly questionable stuff.
I was pretty shocked when I discovered how artificial sweeteners were generally discovered. It frequently involved a laboratory where unknown chemicals accidentally wound up in some researcher's mouth.
Saccharin was produced first in 1879, by Constantin Fahlberg, a chemist working on coal tar derivatives in Ira Remsen's laboratory at Johns Hopkins University.[21] Fahlberg noticed a sweet taste on his hand one evening, and connected this with the compound benzoic sulfimide on which he had been working that day.[22][23]
Cyclamate was discovered in 1937 at the University of Illinois by graduate student Michael Sveda. Sveda was working in the lab on the synthesis of an antipyretic drug. He put his cigarette down on the lab bench, and when he put it back in his mouth, he discovered the sweet taste of cyclamate.[3][4]
Aspartame was discovered in 1965 by James M. Schlatter, a chemist working for G.D. Searle & Company. Schlatter had synthesized aspartame as an intermediate step in generating a tetrapeptide of the hormone gastrin, for use in assessing an anti-ulcer drug candidate.[54] He discovered its sweet taste when he licked his finger, which had become contaminated with aspartame, to lift up a piece of paper.[10][55]
Acesulfame potassium was developed after the accidental discovery of a similar compound (5,6-dimethyl-1,2,3-oxathiazin-4(3H)-one 2,2-dioxide) in 1967 by Karl Clauss and Harald Jensen at Hoechst AG.[16][17] After accidentally dipping his fingers into the chemicals with which he was working, Clauss licked them to pick up a piece of paper.[18]
Sucralose was discovered in 1976 by scientists from Tate & Lyle, working with researchers Leslie Hough and Shashikant Phadnis at Queen Elizabeth College (now part of King's College London).[16] While researching novel uses of sucrose and its synthetic derivatives, Phadnis was told to "test" a chlorinated sugar compound. According to an anecdotal account, Phadnis thought Hough asked him to "taste" it, so he did and found the compound to be exceptionally sweet.[17]
Maybe we'll find that glue pizza works.
Haha, that happens way too often!
I really like reading about accidental discoveries. But the most fun one has to be Silly Putty. 😃
Yeah, chemistry is so fucking complex and unpredictable that most of it happens by accident. Especially for really complex compounds like pharmaceuticals. We basically try a huge number of different things and find out what it does. (Hopefully only good things, a lot of drugs do some good and some bad.)
Those German chemists from the turn of the century were freaking bonkers. They were just synthesiIng random crap and finding all the properties they could. Common practice back then was to taste any compound you synthesized
I'm just thinking of all the really dumb shit we all said on Reddit as satire. Oh I need to go search military meme stuff!
because its stock continues to skyrocket behind the exciting news that AI will continue to be shoved into every aspect of all of its products until morale improves,
Okay, I have to admit, this made me laugh. Definitely commentary, but still, a good read.
Can reddit just fucking die off?
Not disagreeing with the sentiment.. But how is this Reddit's fault? This is entirely on Google.
They also highlight the fact that Google’s AI is not a magical fountain of new knowledge, it is reassembled content from things humans posted in the past indiscriminately scraped from the internet and (sometimes) remixed to look like something plausibly new and “intelligent.”
This. "AI" isn't coming up with new information on its own. The current state of "AI" is a drooling moron, plagiarizing any random scrap of information it sees in a desperate attempt to seem smart. The people promoting AI are scammers.
I mean in this case it's probably more accurately web search results being fed into an LLM and asked to summarize said results. Which if web search results were consistently good and helpful might be a useful feature instead of the thing you skip past and look for links to something useful.
Yeah, just like that x-files episode with the sushi and the theme of teaching them well.
Have you forgotten the reasoning power of artificial intelligence?
I Googled some extremely invasive weed(creeping buttercup) and Google suggested to let it be, quoting some awful reddit comment.
I googled how to increase my blue tooth range and was told to place the devices closer to each other.
Imagine using the resources of a small country just to generate responses to questions that have the same reliability and verifiability of your stoner older brother remembering something he read online.
Not even something he said online. Just something he said to fuck with. This is why i have never understood why people want to use LLM chatbots. The information is so prone to shit like this that it just doesn't seem worth the effort to me. Let alone the energy drain.
For example, as the prophecy foretold, we are learning exactly what Google is paying Reddit $60 million annually for.
You don't have to pay anything to train on the wisdom of the crowd on Fediverse!
To prevent that, just add a magic license statement to the end of all your comments.
/s (sadly, this actually needs it.)
At least this is not "Google Is Paying Lemmy $60 Million for Fucksmith to Tell Its Lemmings to Eat Glue" otherwise I would be wondering why Lemmy Admins are excepting huge wads of cash from tech giants.
You do realize that every posted on the Fediverse is open and publicly available? It’s not locked behind some API or controlled by any one company or entity.
Fediverse is the Wikipedia of encyclopedias and any researcher or engineer, including myself, can and will use Lemmy data to create AI datasets with absolutely no restrictions.
Fediverse is the Wikipedia of encyclopedias
Isn't Wikipedia the Wikipedia of encyclopedias?
I personally don't have nearly as much of a problem with that than I do with Reddit making AI deals. I'm still not keen on the idea of having anything I interact with being scraped for training AI, but aside from only interacting in closed wall spaces that I or someone I trust controls, I can't change that. That'a not great for actually interacting with the world though, so it seems that I need to accept that scraping is going to happen. Given that, I'd definitely rather be on Lemmy than Reddit.
And this way, who knows, maybe we're on our way to the almost utopian "open digital commons"
Just wait until they start scraping the chans
I expect it to create the next Qanon.
When do they announce a deal with 4chan?
Hey Google, when is Jenny available to meet up for kisses?
Is this real though? Does ChatGPT just literally take whole snippets of texts like that? I thought it used some aggregate or probability based on the whole corpus of text it was trained on.
It does, but the thing with the probability is that it doesn't always pick the most likely next bit of text, it basically rolls dice and picks maybe the second or third or in rare cases hundredth most likely continuation. This chaotic behaviour is part of what makes it feel "intelligent" and why it's possible to reroll responses to the same prompt.
I remember doing ghetto text generation in my NLP (Natural Language Processing) class, and the logic was basically this:
- Associate words with a probability number - e.g. given the word "math": "homework" has 25% chance, "class" has 20% chance, etc; these probabilities are generated from the training data
- Generate a random number to decide which word to pick next - average roll gives likely response, less likely roll gives less likely response
- Repeat for as long as you need to generate text
This is a rough explanation of Baysian nets, which I think are what's used in LLMs. We used a very simple n-gram model (e.g. n words are considered for the statistics, e.g. "to my math" is much more likely to generate "class" than "homework"), but they're probably doing fancy things with text categorization and whatnot to generate more relevant text.
The LLM isn't really "thinking" here, it's just associating input text and the training data to generate output text.
Back in my day, we called that “hard-mode plagiarism.” They can’t punish you if they can’t find a specific plagiarized source!
This is not the model directly but the model looking through Google searches to give you an answer.
Where's Infinite Solutions when you need him
It’s called electrical tape because it conducts electricity
Cyanoacrylate or elmers?
shitpost is praxis
I once said that the current "AI" is just a excel spread sheet with a few billion rows, from what all of the answer gets interpolated from...
AI will continue to be shoved into every aspect of all of its products until morale improves
Stahp! I can only get so hard!
It's so fucking stupid
It's got electrolytes tho fr fr no cap
I like money
My favorite is the Google bot just regurgitating the top result. Which gives that result exactly zero traffic while having absolutely no quality control, mind you.
I wonder what cuil things it will say if you start asking questions about hamburgers instead...
I primed ChatGPT with cuil theory (which it already knew) and here's what it came up with
You ask me for a hamburger. I nod and walk into the kitchen, but instead of returning with a hamburger, I bring you a picture of a hamburger. Confused, you ask again, and this time I present you with a photograph of you asking for a hamburger. Frustrated, you repeat your request, and I hand you an intricate painting of the universe, meticulously devoid of any trace of hamburgers. Baffled, you insist once more, and suddenly, a trout appears, reciting lines from Shakespeare's "Hamlet." Undeterred, you ask again, and I give you a detailed map of Atlantis, with all the continents shaped like hamburgers. Your persistence leads me to produce an ancient scroll, describing a hamburger in a forgotten language. As your patience wears thin, I conjure a sentient cloud that dreams of becoming a hamburger. Still seeking a hamburger, you find yourself transported to a dimension where hamburgers debate human rights. Finally, a symphony envelops you, its notes tasting like a hamburger. At your final request, the fabric of reality unravels, and in an existential twist, you become the hamburger you so desperately sought.
Not bad. Doesn't look like it cribbed directly from any existing texts, at least as far as I can tell by searching Google for "cuil hamburger hamlet atlantis".
Money well spent.
Speaking of, I found a recipe today which had to have been ai generated because the ingredient list and the directions were for completely different recipes
Now I only regret not *EDITING all of my Reddit posts to say complete nonsense when I deleted my account June 2023. Instead I deleted each and every post and requested a copy of my data to cost them money.
I'm sure they used a dataset from before people started editing and deleting stuff.
enhaced flavor
Beautiful.
How to get more absolute shit from Goog?
That headline really is a thing of beauty. It's like finding out that your trash is piling up because the city retasked all the sanitation workers to lie in fields of filth and create a heavenly host of garbage angels.
reddit is shit no thanks to spez and his shenanigans.
people should just boycott reddit so that none of this ai nonsense ever gets posted to people looking for stuff.
How did this clickbaity headline got so many upvotes? Are we really cherry-picking some outlier example of a hallucination and using it to say "haha, google dumb"? I think there is plenty of valid criticism out there against google that we can stick to instead of paying attention to stupid and provocative articles
I mean, how about my boring example from work the other day? I wanted to double check whether priority mail had guaranteed delivery timeframes before telling a customer that they did not and if she needed something by a specific day she should use UPS. When I searched "is priority mail delivery date guaranteed", the first real answer, from USPS's website, was a resounding no, just like I thought. Guess what Google's AI told me? "Priority mail is a guaranteed service, so you can choose it knowing that your package will be delivered on the projected date."
It's fucking stupid. It's wrong. It should not be at the top of search results.